
مقدمه
در مدلهای زبان که به دنبال کارایی و دقت هستند، Llama 3.1 Storm 8B به عنوان یک دستاورد قابل توجه ظاهر میشود. این نسخه دقیق از متا Llama 3.1 8B Instruct نشان دهنده جهشی به جلو در بهبود قابلیت های مکالمه و فراخوانی عملکرد در کلاس مدل پارامتر 8B است. سفر به این پیشرفت ریشه در رویکردی دقیق دارد که حول پردازش دادهها متمرکز است، جایی که نمونههای آموزشی با کیفیت بالا به دقت انتخاب میشوند تا پتانسیل مدل را به حداکثر برسانند.
روند تنظیم دقیق به همین جا ختم نشد. از طریق تنظیم دقیق مبتنی بر طیف هدفمند پیشرفت کرد و در ادغام الگوهای استراتژیک به اوج رسید. این مقاله تکنیکهای نوآورانهای را مورد بحث قرار میدهد که Llama 3.1 Storm 8B را به پیشی گرفتن از پیشینیان خود سوق داد و استاندارد جدیدی را در مدلهای زبان کوچک ایجاد کرد.

Llama-3.1-Storm-8B چیست؟
Llama-3.1-Storm-8B بر اساس نقاط قوت Llama-3.1-8B-Instruct ساخته شده و قابلیت فراخوانی و فراخوانی عملکرد را در کلاس مدل پارامتر 8B بهبود می بخشد. این ارتقاء پیشرفتهای قابلتوجهی را در معیارهای متعدد، از جمله پیروی از دستورالعمل، مدیریت کیفیت مبتنی بر دانش، استدلال، کاهش توهم و فراخوانی عملکرد نشان میدهد. این پیشرفت ها به نفع توسعه دهندگان و علاقه مندان به هوش مصنوعی است که با منابع محاسباتی محدود کار می کنند.
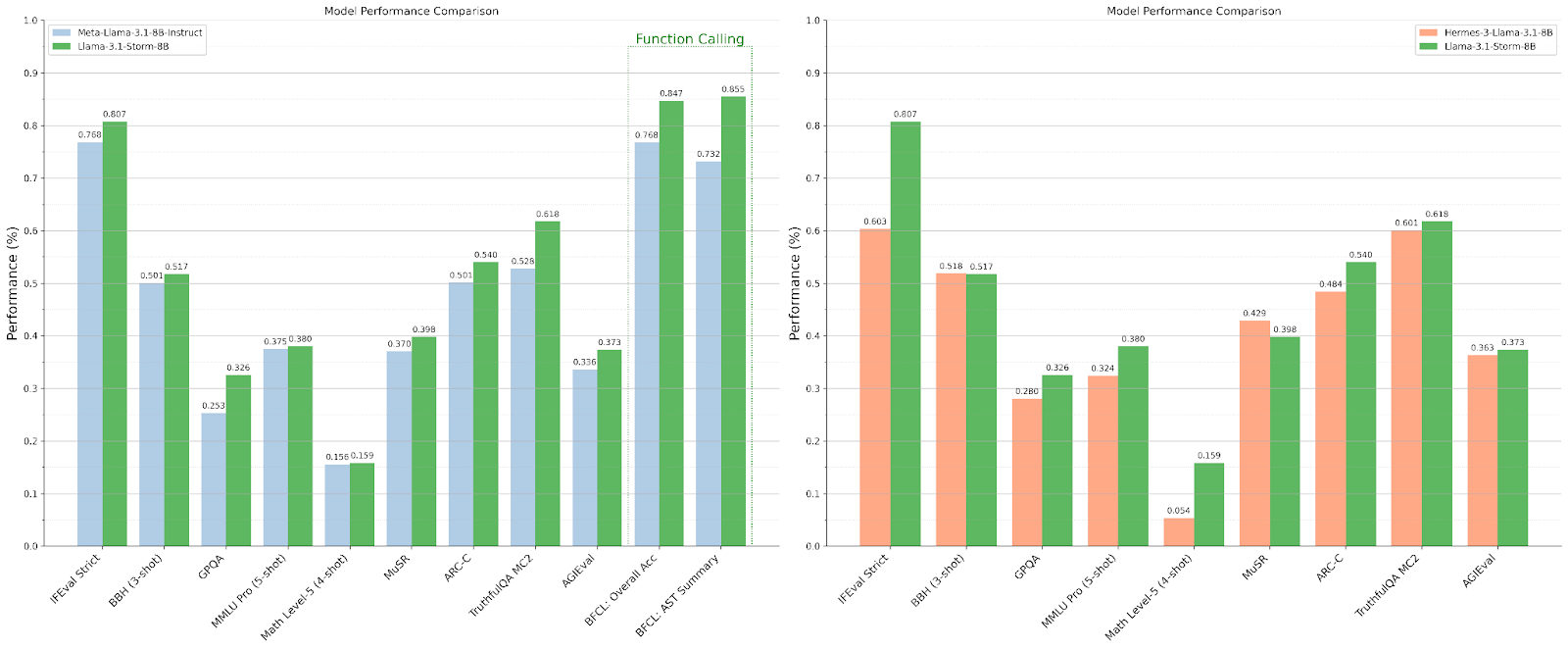
در مقایسه با مدل اخیر Hermes-3-Llama-3.1-8B، Llama-3.1-Storm-8B از 7 معیار از 9 معیار برتری دارد. Hermes-3 تنها در معیار MuSR پیشتاز است و هر دو مدل در معیار BBH عملکرد مشابهی دارند.
Lama 3.1 Storm 8B نقاط قوت
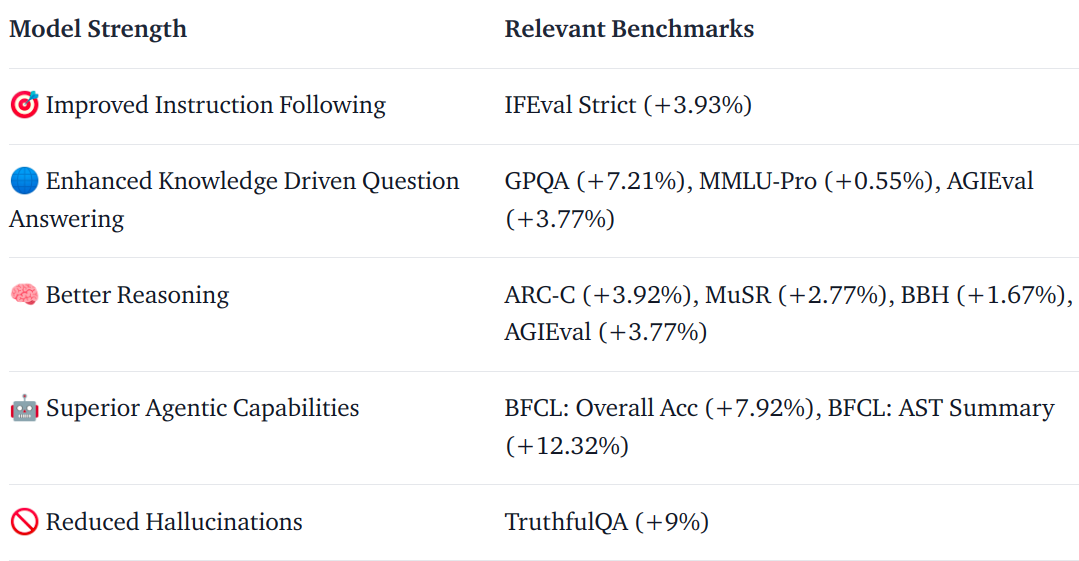
تصویر بالا نشان دهنده پیشرفت ها (افزایش مطلق) نسبت به Llama 3.1 8B Instruct است.
مدل های Llama 3.1 Storm 8B
در اینجا مدل های Llama 3.1 Storm 8B آمده است:
- Llama 3.1 Storm 8B: این مدل اولیه با تنظیم دقیق است.
- Llama 3.1 Storm 8B FP8 Dynamic: این اسکریپت وزنها و فعالسازیهای Llama-3.1-Storm-8B را به نوع داده FP8 تقسیم میکند و در نتیجه مدلی آماده برای استنتاج vLLM است. با کاهش تعداد بیت ها در هر پارامتر از 16 به 8، این بهینه سازی تقریباً 50 درصد از حافظه GPU و فضای دیسک مورد نیاز را ذخیره می کند.
وزن ها و فعال سازی عملگرهای خطی تنها عناصر کوانتیزه شده در بلوک های ترانسفورماتور هستند. نمایشهای FP8 از این وزنها و فعالسازیهای کوانتیزه شده با استفاده از یک تکنیک مقیاسبندی خطی منفرد به نام کوانتیزاسیون تانسور متقارن نقشهبرداری میشوند. 512 توالی UltraChat با استفاده از کمپرسور LLM کوانتیزه می شوند.
- Llama 3.1 Storm 8B GGUF: این یک نسخه کوانتیزه شده GGUF از Llama-3.1-Storm-8B برای استفاده در llama.cpp است. GGUF یک فرمت فایل برای ذخیره مدل ها برای رندر با رندرهای مبتنی بر GGML و GGML است. GGUF یک فرمت باینری است که برای بارگذاری سریع و ذخیره مدل ها و برای خواندن آسان طراحی شده است. مدل ها به طور سنتی با استفاده از PyTorch یا فریمورک دیگری توسعه داده می شوند و سپس برای استفاده در GGML به GGUF تبدیل می شوند. این یک فرمت فایل جانشین برای GGML، GGMF و GGJT است و به گونهای طراحی شده است که بدون ابهام باشد و حاوی تمام اطلاعات مورد نیاز برای بارگذاری یک مدل باشد. همچنین به گونه ای طراحی شده است که قابل توسعه باشد به طوری که می توان اطلاعات جدیدی را بدون شکستن سازگاری به مدل ها اضافه کرد.
همچنین بخوانید: Meta Llama 3.1: آخرین مدل AI منبع باز با GPT-4o mini مقابله می کند
رویکرد بعدی
نمودار مقایسه عملکرد نشان می دهد که Llama 3.1 Storm 8B به طور قابل توجهی از Llama 3.1 8B Instruct و Hermes 3 Llama 3.1 8B متا AI در معیارهای مختلف بهتر عمل می کند..
رویکرد آنها شامل 3 مرحله اصلی است:
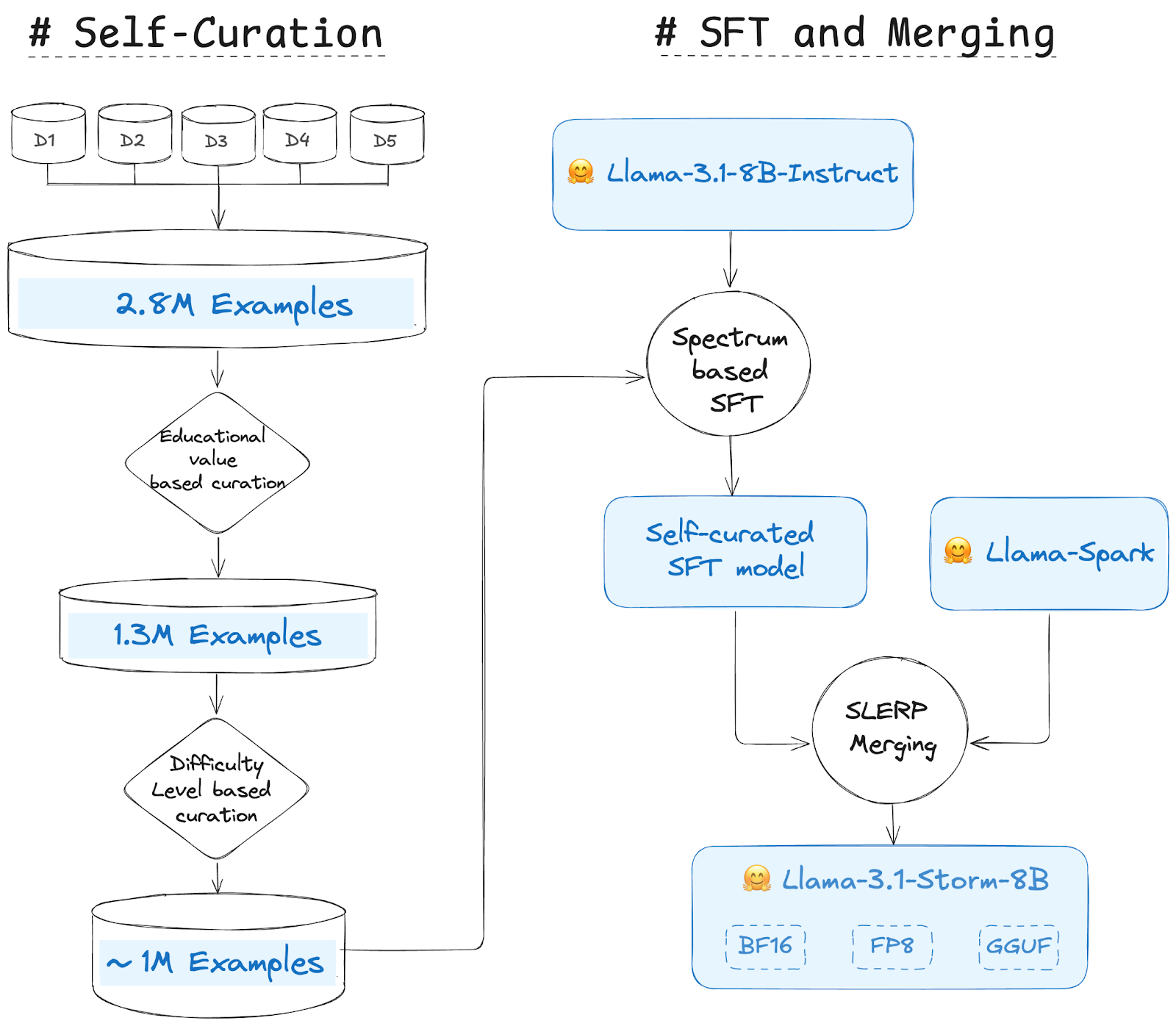
خوددرمانی
مجموعه داده های منبع مورد استفاده برای Llama 3.1 Storm 8B این 5 مجموعه داده منبع باز هستند (The-Tome، agent-data، Magpie-Llama-3.1-Pro-300K-Filtered، openhermes_200k_unfiltered، Llama-3-Magpie- PO-100K-SML) . مجموعه داده های ترکیبی شامل 2.8 میلیون نمونه است. به هر نمونه پردازش داده یک مقدار یا مقادیر داده می شود و سپس بسته به مقدار یا مقادیر اختصاص داده شده به هر نمونه، قضاوت انتخاب انجام می شود. مدلهای LLM یا یادگیری ماشین معمولاً برای تخصیص چنین مقادیری استفاده میشوند. با استفاده از LLM، چندین رویکرد برای ارزش دادن به یک مثال وجود دارد. ارزش آموزشی و سطح دشواری دو مورد از رایج ترین معیارهای مورد استفاده برای ارزیابی نمونه ها هستند.
ارزش یا آموزنده بودن مثال (دستورالعمل + پاسخ) با ارزش آموزشی آن و درجه سختی آن با سطح دشواری تعیین می شود. ارزش آموزشی بین 1 تا 5 است که در آن 1 کمترین آموزشی و 5 آموزشی ترین است. 3 سطح دشواری وجود دارد – آسان، متوسط و سخت. هدف بهبود QMS در زمینه خوددرمانی است. بنابراین ما بر اجرای همان الگو تمرکز کردیم – از Llama-3.1-8B-Instruct به جای Llama-3.1-70B-Instruct، Llama-3.1-405B-Instruct و سایر LLM های بزرگتر استفاده کنید.
مراحل خودکنترلی:
- مرحله 1: آموزش آماده سازی مبتنی بر ارزش – آنها از Llama 3.1 Instruct 8B برای اختصاص یک ارزش آموزشی (1-5) به همه نمونه ها (~2.8 میلیون) استفاده کردند. آنها سپس نمونه هایی را با امتیاز بیشتر از 3 انتخاب کردند. آنها رویکرد مجموعه داده FineWeb-Edu را دنبال کردند. این مرحله تعداد کل نمونه ها را از 2.8 میلیون به 1.3 میلیون کاهش داد.
- مرحله 2: تنظیم بر اساس سطح دشواری – ما از رویکرد مشابهی پیروی می کنیم و از Llama 3.1 Instruct 8B برای اختصاص سطح دشواری (آسان، متوسط و سخت) به 1.3 میلیون مثال از مرحله قبل استفاده می کنیم. پس از چندین آزمایش، نمونه هایی را برای سطح متوسط و سخت انتخاب کردند. این استراتژی شبیه به کوتاه کردن داده ها است که در گزارش فنی Llama-3.1 توضیح داده شده است. ~650K و ~325K نمونه با درجه سختی متوسط و سخت به ترتیب وجود داشت.
مجموعه داده انتخابی نهایی حاوی 975 هزار نمونه است. سپس 960K و 15K به ترتیب برای آموزش و اعتبار سنجی تقسیم شدند.
تنظیم دقیق دستورالعمل های کنترل شده هدف
مدل Self Curation که با مدل Llama-3.1-8B-Instruct با 960 هزار نمونه در 4 دوره تنظیم شده است، از Spectrum استفاده می کند، روشی که آموزش LLM را با هدف قرار دادن انتخابی ماژول های لایه بر اساس نسبت سیگنال به نویز آنها تسریع می کند. SNR ) در حین انجماد بقیه. Spectrum با اولویت بندی لایه های با SNR بالا و انجماد 50 درصد از لایه های کم SNR، عملکرد تنظیم دقیق کامل را با کاهش مصرف حافظه GPU به طور موثر ترکیب می کند. مقایسه با روش هایی مانند QLoRA کیفیت برتر مدل Spectrum و کارایی VRAM را در محیط های توزیع شده نشان می دهد.
ادغام مدل ها
از آنجایی که ادغام مدل منجر به برخی از مدلهای پیشرفته شده است، آنها تصمیم گرفتند مدل خودساخته و دقیق را با مدل Llama Spark که مشتق شده از Llama 3.1 8B Instruct است، ادغام کنند. آنها از روش SLERP برای ادغام این دو مدل استفاده کردند و یک مدل ترکیبی ایجاد کردند که ماهیت هر دو والدین را از طریق درون یابی صاف به تصویر می کشد. درونیابی خطی کروی (SLERP) با حفظ خواص هندسی فضای کروی، نرخ ثابتی از تغییر را فراهم میکند و به مدل حاصل اجازه میدهد تا ویژگیهای کلیدی هر دو مدل والد را حفظ کند. ما می توانیم معیارهایی را ببینیم که در آن مدل Self-Curation SFT به طور متوسط از مدل Llama-Spark بهتر است. با این حال، مدل تلفیقی حتی بهتر از هر دو مدل عمل می کند.
تأثیر خودنگهداری و ادغام مدل
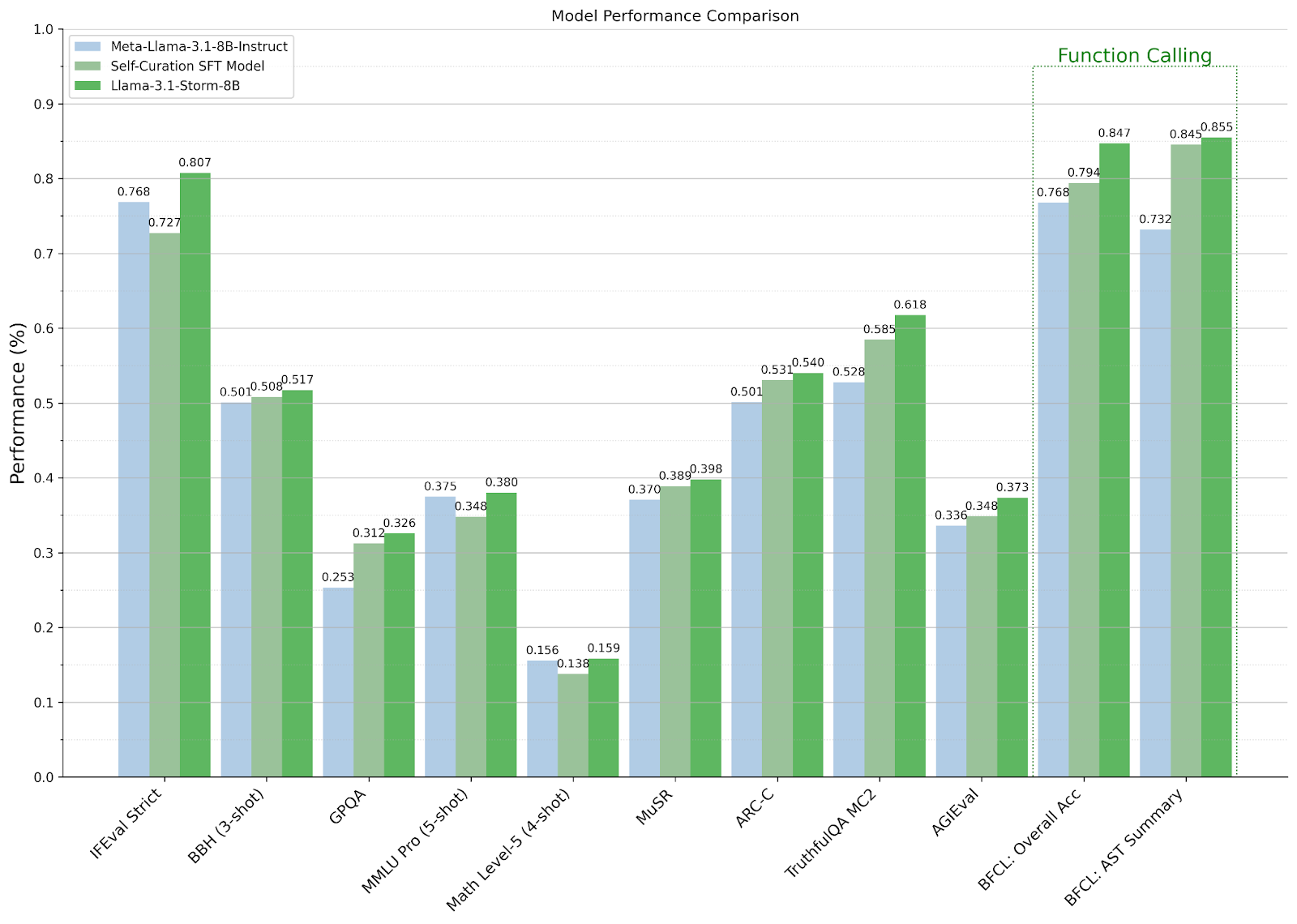
همانطور که شکل بالا نشان می دهد، استراتژی SFT مبتنی بر نظارت بر خود از Llama-3.1-8B-Instruct در 7 معیار از 10 معیار بهتر عمل می کند و اهمیت انتخاب نمونه های با کیفیت را برجسته می کند. این نتایج همچنین نشان می دهد که انتخاب مدل ترکیبی مناسب می تواند عملکرد را در بین معیارهای ارزیابی شده بهبود بخشد.
نحوه استفاده از مدل Llama 3.1 Storm 8B
ما از کتابخانه ترانسفورماتور Hugging Face برای استفاده از مدل Llama 3.1 Storm 8B استفاده خواهیم کرد. به طور پیش فرض، ترانسفورماتورها مدل را در bfloat16 بارگذاری می کنند، که نوعی از آن در تنظیم دقیق است. استفاده از آن توصیه می شود.
روش 1: از خط لوله ترانسفورماتور استفاده کنید
1 مرحله: نصب کتابخانه های مورد نیاز
!pip install --upgrade "transformers>=4.43.2" torch==2.3.1 accelerate flash-attn==2.6.3مرحله 2: مدل Llama 3.1 Storm 8B را بارگیری کنید
import transformers
import torch
model_id = "akjindal53244/Llama-3.1-Storm-8B"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)مرحله سوم: یک متد کمکی برای ایجاد ورودی مدل ایجاد کنید
def prepare_conversation(user_prompt):
# Llama-3.1-Storm-8B chat template
conversation = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": user_prompt}
]
return conversationمرحله چهارم: نتیجه را بگیرید
# User query
user_prompt = "What is the capital of Spain?"
conversation = prepare_conversation(user_prompt)
outputs = pipeline(conversation, max_new_tokens=128, do_sample=True, temperature=0.01, top_k=100, top_p=0.95)
response = outputs[0]['generated_text'][-1]['content']
print(f"Llama-3.1-Storm-8B Output: {response}")
روش 2: با استفاده از مدل API، tokenizer و model.generate
1 مرحله: مدل و توکنایزر Llama 3.1 Storm 8B را بارگیری کنید
import torch
from transformers import AutoTokenizer, LlamaForCausalLM
model_id = 'akjindal53244/Llama-3.1-Storm-8B'
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = LlamaForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
load_in_8bit=False,
load_in_4bit=False,
use_flash_attention_2=False # Colab Free T4 GPU is an old generation GPU and does not support FlashAttention. Enable if using Ampere GPUs or newer such as RTX3090, RTX4090, A100, etc.
)مرحله 2: الگوی چت Llama-3.1-Storm-8B را اعمال کنید
def format_prompt(user_query):
template = """<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nYou are a helpful assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>\n\n{}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n"""
return template.format(user_query)3 مرحله: خروجی را از مدل بگیرید
# Build final input prompt after applying chat-template
prompt = format_prompt("What is the capital of France?")
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to("cuda")
generated_ids = model.generate(input_ids, max_new_tokens=128, temperature=0.01, do_sample=True, eos_token_id=tokenizer.eos_token_id)
response = tokenizer.decode(generated_ids[0][input_ids.shape[-1]:], skip_special_tokens=True)
print(f"Llama-3.1-Storm-8B Output: {response}")
نتیجه گیری
Llama 3.1 Storm 8B یک گام مهم رو به جلو در توسعه مدل های زبانی کارآمد و قدرتمند است. این نشان میدهد که مدلهای کوچکتر میتوانند از طریق تکنیکهای نوآورانه یادگیری و ترکیب، به عملکرد چشمگیری دست یابند و راههای جدیدی را برای تحقیق و توسعه برنامههای کاربردی هوش مصنوعی باز کنند. با ادامه توسعه این زمینه، انتظار داریم که اصلاحات و کاربردهای بیشتری از این تکنیک ها را شاهد باشیم که به طور بالقوه دسترسی به قابلیت های پیشرفته هوش مصنوعی را دموکراتیک می کند.
با GenAI Pinnacle خود را در آینده هوش مصنوعی غرق کنید. پروژه های خود را با قابلیت های پیشرفته، از آموزش مدل های سفارشی گرفته تا مقابله با چالش های دنیای واقعی مانند پوشاندن PII، قدرتمند کنید. شروع به کاوش کنید.
سوالات متداول
پاسخ دهید Llama 3.1 Storm 8B یک مدل زبان کوچک (SLM) با 8 میلیارد پارامتر بهبود یافته است که بر روی مدل متا AI Llama 3.1 8B Instruct با استفاده از خود نظارتی، تنظیم دقیق هدفمند و تکنیکهای ترکیب مدل ساخته شده است.
پاسخ دهید در معیارهای مختلف از Llama 3.1 8B Instruct و Hermes-3-Llama-3.1-8B متا بهتر عمل می کند و پیشرفت های قابل توجهی را در زمینه هایی مانند دنبال کردن دستورالعمل، QA مبتنی بر دانش، استدلال و فراخوانی عملکرد نشان می دهد.
پاسخ دهید این مدل با استفاده از یک فرآیند سه مرحلهای ساخته شد: پردازش دادههای آموزشی مستقل، تنظیم دقیق هدفمند با استفاده از روش Spectrum، و ترکیب مدل با Llama-Spark با استفاده از تکنیک SLERP.
پاسخ دهید توسعه دهندگان می توانند به راحتی مدل را با استفاده از کتابخانه های محبوب مانند Transformers و vLLM در پروژه های خود ادغام کنند. این در قالبهای مختلف (BF16، FP8، GGUF) ارائه میشود و میتواند برای کارهای مختلفی از جمله هوش مصنوعی مکالمه و فراخوانی ویژگیها استفاده شود.