
مقدمه
در قسمت دوم مجموعه ما در مورد ساختن یک برنامه RAG بر روی Raspberry Pi، پایهای را که در قسمت اول ایجاد کردیم و خط لوله اصلی را آزمایش کردیم، گسترش خواهیم داد. در قسمت اول، خط لوله اصلی را ایجاد کردیم و آن را آزمایش کردیم تا مطمئن شویم همه چیز مطابق انتظار کار می کند. اکنون با ساختن یک برنامه کاربردی FastAPI برای خدمت رسانی به خط لوله RAG و ساختن یک برنامه Reflex به منظور ارائه یک راه ساده و تعاملی به کاربران برای دسترسی به آن، کارها را یک قدم جلوتر برداریم. این بخش شما را در راهاندازی بکاند FastAPI، طراحی ظاهری با Reflex و راهاندازی همه چیز در Raspberry Pi خود راهنمایی میکند. در پایان، یک برنامه کامل و کارآمد خواهید داشت که برای استفاده در دنیای واقعی آماده است.
اهداف آموزشی
- بکاند FastAPI را برای ادغام با خط لوله RAG موجود پیکربندی کنید و درخواستها را به طور موثر پردازش کنید.
- یک رابط کاربر پسند با استفاده از Reflex برای تعامل با خط لوله FastAPI و RAG طراحی کنید.
- ایجاد و تست پرس و جوی API نقاط پایانی و انتقال سند، اطمینان از عملکرد روان با FastAPI.
- کل برنامه را روی Raspberry Pi اجرا و آزمایش کنید و از عملکرد روان اجزای Back-end و Front-end اطمینان حاصل کنید.
- ادغام بین FastAPI و Reflex را برای تجربه یکپارچه برنامه RAG درک کنید.
- پیاده سازی و عیب یابی اجزای FastAPI و Reflex برای ارائه یک برنامه RAG کاملاً کاربردی در Raspberry Pi.
اگر نسخه قبلی را از دست دادید، حتماً آن را اینجا ببینید: خود میزبانی برنامه های RAG در دستگاه های لبه با Langchain و Ollama – قسمت اول.
این مقاله به عنوان بخشی از بلاگاتون علم داده.
ایجاد محیط پایتون
قبل از شروع ساخت اپلیکیشن، باید محیط را تنظیم کنیم. یک محیط ایجاد کنید و وابستگی های زیر را نصب کنید:
deeplake
boto3==1.34.144
botocore==1.34.144
fastapi==0.110.3
gunicorn==22.0.0
httpx==0.27.0
huggingface-hub==0.23.4
langchain==0.2.6
langchain-community==0.2.6
langchain-core==0.2.11
langchain-experimental==0.0.62
langchain-text-splitters==0.2.2
langsmith==0.1.83
marshmallow==3.21.3
numpy==1.26.4
pandas==2.2.2
pydantic==2.8.2
pydantic_core==2.20.1
PyMuPDF==1.24.7
PyMuPDFb==1.24.6
python-dotenv==1.0.1
pytz==2024.1
PyYAML==6.0.1
reflex==0.5.6
requests==2.32.3
reflex==0.5.6
reflex-hosting-cli==0.1.13پس از نصب پکیج های مورد نیاز باید مدل های مورد نیاز را در دستگاه داشته باشیم. ما این کار را با کمک اولاما انجام خواهیم داد. برای دانلود زبان و الگوهای جاسازی مراحل قسمت 1 این مقاله را دنبال کنید. در نهایت، دو دایرکتوری برای برنامه های Back-end و Front-end ایجاد کنید.
هنگامی که مدل ها با استفاده از Ollama دانلود شدند، ما آماده ساختن برنامه نهایی هستیم.
توسعه Back-end با FastAPI
در قسمت 1 این مقاله، خط لوله RAG را ساختیم که دارای هر دو ماژول دریافت و QnA است. ما هر دو خط لوله را با استفاده از برخی اسناد آزمایش کردیم و آنها کاملاً کار کردند. اکنون باید خط لوله را با FastAPI بپیچیم تا یک Consumables API ایجاد کنیم. این به ما کمک می کند تا آن را با هر برنامه جلویی مانند Streamlit، Chainlit، Gradio، Reflex، React، Angular و غیره ادغام کنیم. بیایید با ساختن یک ساختار برای برنامه شروع کنیم. پیروی از ساختار کاملاً اختیاری است، اما اگر از ساختار دیگری برای ساخت برنامه پیروی میکنید، حتماً وابستگیهای واردات را بررسی کنید.
در زیر ساختار درختی را مشاهده خواهیم کرد:
backend
├── app.py
├── requirements.txt
└── src
├── config.py
├── doc_loader
│ ├── base_loader.py
│ ├── __init__.py
│ └── pdf_loader.py
├── ingestion.py
├── __init__.py
└── qna.pyبیایید با config.py شروع کنیم. این فایل شامل تمام گزینه های قابل تنظیم برای برنامه است، مانند URL Ollama، نام LLM، و نام مدل جاسازی شده. در زیر یک مثال آورده شده است:
LANGUAGE_MODEL_NAME = "phi3"
EMBEDDINGS_MODEL_NAME = "nomic-embed-text"
OLLAMA_URL = "http://localhost:11434"فایل base_loader.py شامل کلاس بارکننده سند والد است که توسط بارکننده سند فرزند به ارث می رسد. در این برنامه ما فقط با فایل های PDF کار می کنیم، بنابراین یک کلاس Child PDFLoader وجود خواهد داشت
ایجاد شده که کلاس BaseLoader را به ارث می برد.
در زیر محتوای base_loader.py و pdf_loader.py آمده است:
# base_loader.py
from abc import ABC, abstractmethod
class BaseLoader(ABC):
def __init__(self, file_path: str) -> None:
self.file_path = file_path
@abstractmethod
async def load_document(self):
pass
# pdf_loader.py
import os
from .base_loader import BaseLoader
from langchain.schema import Document
from langchain.document_loaders.pdf import PyMuPDFLoader
from langchain.text_splitter import CharacterTextSplitter
class PDFLoader(BaseLoader):
def __init__(self, file_path: str) -> None:
super().__init__(file_path)
async def load_document(self):
self.file_name = os.path.basename(self.file_path)
loader = PyMuPDFLoader(file_path=self.file_path)
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=200,
)
pages = await loader.aload()
total_pages = len(pages)
chunks = []
for idx, page in enumerate(pages):
chunks.append(
Document(
page_content=page.page_content,
metadata=dict(
{
"file_name": self.file_name,
"page_no": str(idx + 1),
"total_pages": str(total_pages),
}
),
)
)
final_chunks = text_splitter.split_documents(chunks)
return final_chunksما در مورد کار pdf_loader در قسمت 1 مقاله بحث کردیم.
بعد، بیایید کلاس جذب را بسازیم. این همان چیزی است که در قسمت 1 این مقاله ایجاد کردیم.
کد کلاس جذب
import os
import config as cfg
from pinecone import Pinecone
from langchain.vectorstores.deeplake import DeepLake
from langchain.embeddings.ollama import OllamaEmbeddings
from .doc_loader import PDFLoader
class Ingestion:
"""Document Ingestion pipeline."""
def __init__(self):
try:
self.embeddings = OllamaEmbeddings(
model=cfg.EMBEDDINGS_MODEL_NAME,
base_url=cfg.OLLAMA_URL,
show_progress=True,
)
self.vector_store = DeepLake(
dataset_path="data/text_vectorstore",
embedding=self.embeddings,
num_workers=4,
verbose=False,
)
except Exception as e:
raise RuntimeError(f"Failed to initialize Ingestion system. ERROR: {e}")
async def create_and_add_embeddings(
self,
file: str,
):
try:
loader = PDFLoader(
file_path=file,
)
chunks = await loader.load_document()
size = await self.vector_store.aadd_documents(documents=chunks)
return len(size)
except (ValueError, RuntimeError, KeyError, TypeError) as e:
raise Exception(f"ERROR: {e}")اکنون که کلاس دریافت کننده را راه اندازی کردیم، به ساخت کلاس QnA می رویم. این نیز همان چیزی است که در قسمت 1 این مقاله ایجاد کردیم.
کد برای کلاس QnA
import os
import config as cfg
from pinecone import Pinecone
from langchain.vectorstores.deeplake import DeepLake
from langchain.embeddings.ollama import OllamaEmbeddings
from langchain_community.llms.ollama import Ollama
from .doc_loader import PDFLoader
class QnA:
"""Document Ingestion pipeline."""
def __init__(self):
try:
self.embeddings = OllamaEmbeddings(
model=cfg.EMBEDDINGS_MODEL_NAME,
base_url=cfg.OLLAMA_URL,
show_progress=True,
)
self.model = Ollama(
model=cfg.LANGUAGE_MODEL_NAME,
base_url=cfg.OLLAMA_URL,
verbose=True,
temperature=0.2,
)
self.vector_store = DeepLake(
dataset_path="data/text_vectorstore",
embedding=self.embeddings,
num_workers=4,
verbose=False,
)
self.retriever = self.vector_store.as_retriever(
search_type="similarity",
search_kwargs={
"k": 10,
},
)
except Exception as e:
raise RuntimeError(f"Failed to initialize Ingestion system. ERROR: {e}")
def create_rag_chain(self):
try:
system_prompt = """<Instructions>\n\nContext: {context}"
"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(self.model, prompt)
rag_chain = create_retrieval_chain(self.retriever, question_answer_chain)
return rag_chain
except Exception as e:
raise RuntimeError(f"Failed to create retrieval chain. ERROR: {e}")این کار ایجاد عملکردهای کد برنامه RAG را تکمیل می کند. حالا بیایید برنامه را با FastAPI بپیچیم.
کد برای برنامه FastAPI
import sys
import os
import uvicorn
from src import QnA, Ingestion
from fastapi import FastAPI, Request, File, UploadFile
from fastapi.responses import StreamingResponse
app = FastAPI()
ingestion = Ingestion()
chatbot = QnA()
rag_chain = chatbot.create_rag_chain()
@app.get("https://www.analyticsvidhya.com/")
def hello():
return {"message": "API Running in server 8089"}
@app.post("/query")
async def ask_query(request: Request):
data = await request.json()
question = data.get("question")
async def event_generator():
for chunk in rag_chain.pick("answer").stream({"input": question}):
yield chunk
return StreamingResponse(event_generator(), media_type="text/plain")
@app.post("/ingest")
async def ingest_document(file: UploadFile = File(...)):
try:
os.makedirs("files", exist_ok=True)
file_location = f"files/{file.filename}"
with open(file_location, "wb+") as file_object:
file_object.write(file.file.read())
size = await ingestion.create_and_add_embeddings(file=file_location)
return {"message": f"File ingested! Document count: {size}"}
except Exception as e:
return {"message": f"An error occured: {e}"}
if __name__ == "__main__":
try:
uvicorn.run(app, host="0.0.0.0", port=8089)
except KeyboardInterrupt as e:
print("App stopped!")بیایید برنامه را بر اساس هر نقطه پایانی تجزیه کنیم:
- ابتدا برنامه FastAPI، اشیاء Ingestion و QnA را مقداردهی اولیه می کنیم. سپس با استفاده از متد create_rag_chain از کلاس QnA یک زنجیره RAG ایجاد می کنیم.
- اولین نقطه پایانی ما یک روش ساده GET است. این به ما کمک می کند که بدانیم آیا برنامه سالم است یا خیر. آن را به عنوان یک نقطه پایانی “Hello World” در نظر بگیرید.
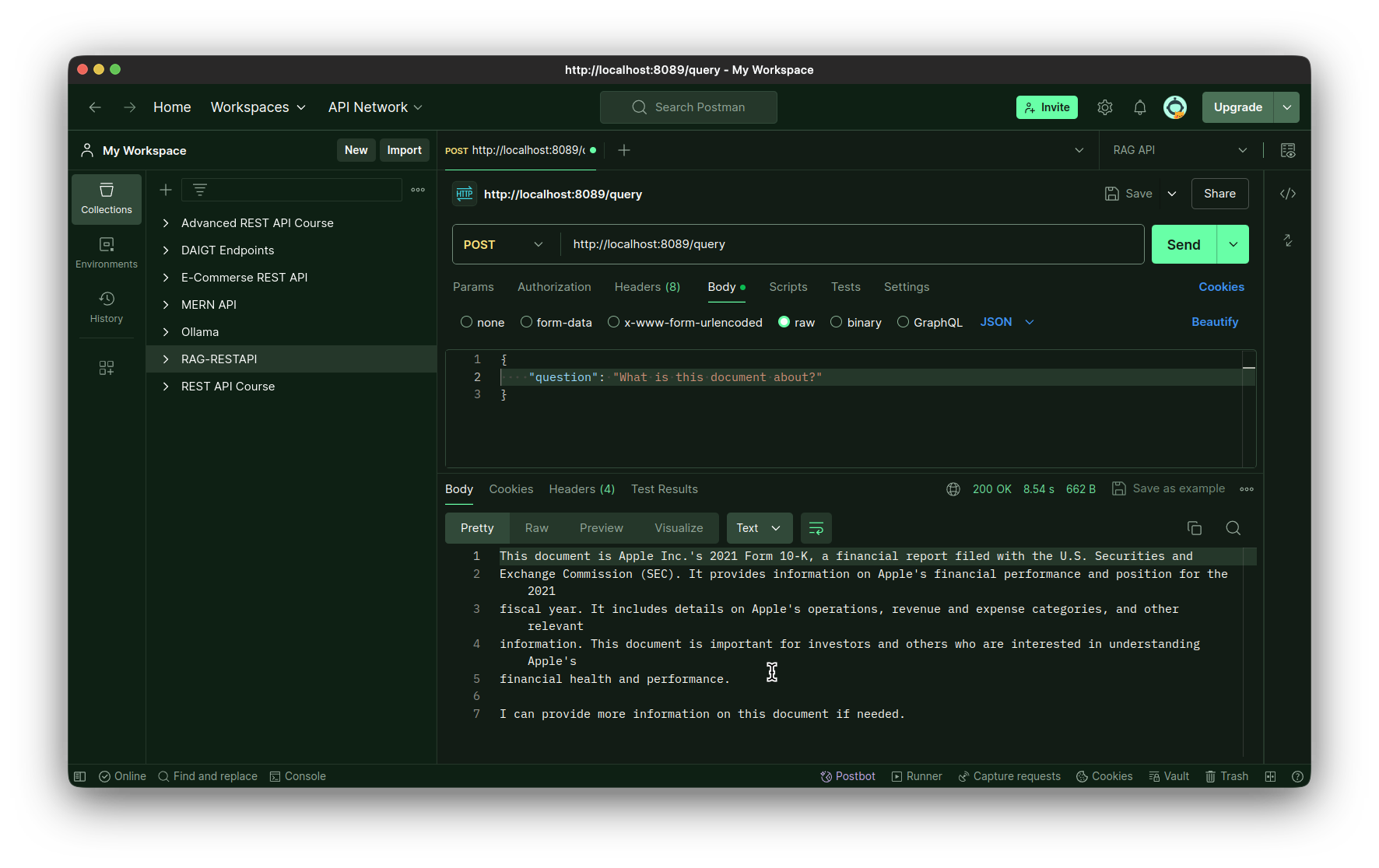
- دوم نقطه پایانی پرس و جو است. این یک روش POST است و برای اجرای زنجیره استفاده می شود. این یک پارامتر پرس و جو را می پذیرد که از آن درخواست کاربر را بازیابی می کنیم. در مرحله بعد، ما یک متد async ایجاد می کنیم که به عنوان یک پوشش ناهمگام در اطراف فراخوانی تابع chain.stream عمل می کند. ما باید این کار را انجام دهیم تا به FastAPI اجازه دهیم تا فراخوانی تابع جریان LLM را انجام دهد تا تجربه ای شبیه به ChatGPT در رابط چت داشته باشد. سپس متد async را با کلاس StreamingResponse می پیچیم و آن را برمی گردانیم.
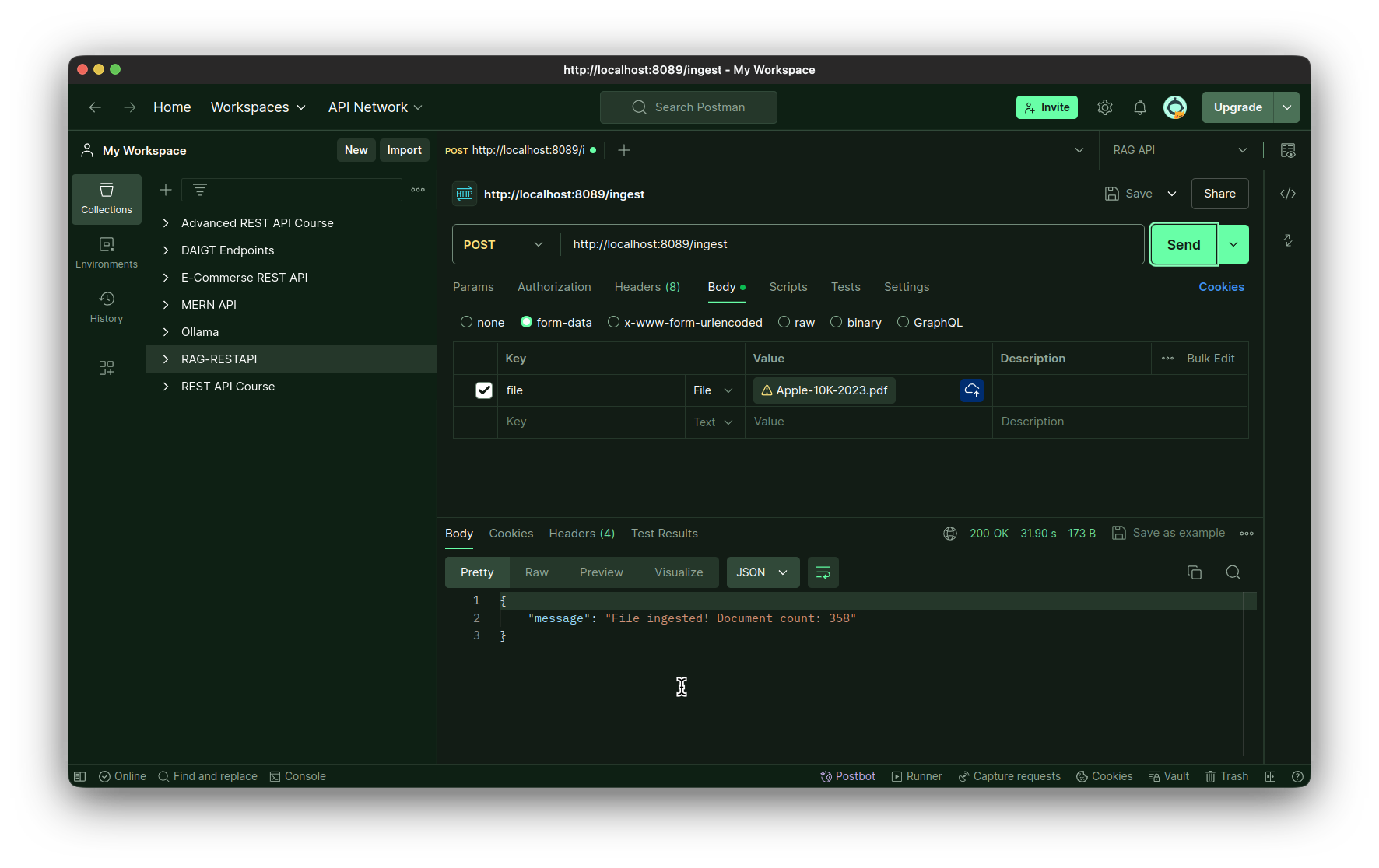
- سومین نقطه پایانی، نقطه پایانی مصرف است. این نیز یک روش POST است که کل فایل را به عنوان بایت به عنوان ورودی می پذیرد. ما این فایل را در دایرکتوری محلی ذخیره می کنیم و سپس آن را با استفاده از متد create_and_add_embeddings کلاس ingest وارد می کنیم.
در نهایت برنامه را با استفاده از بسته uvicorn با استفاده از هاست و پورت اجرا می کنیم. برای تست برنامه کافیست با استفاده از دستور زیر برنامه را اجرا کنید:
python app.py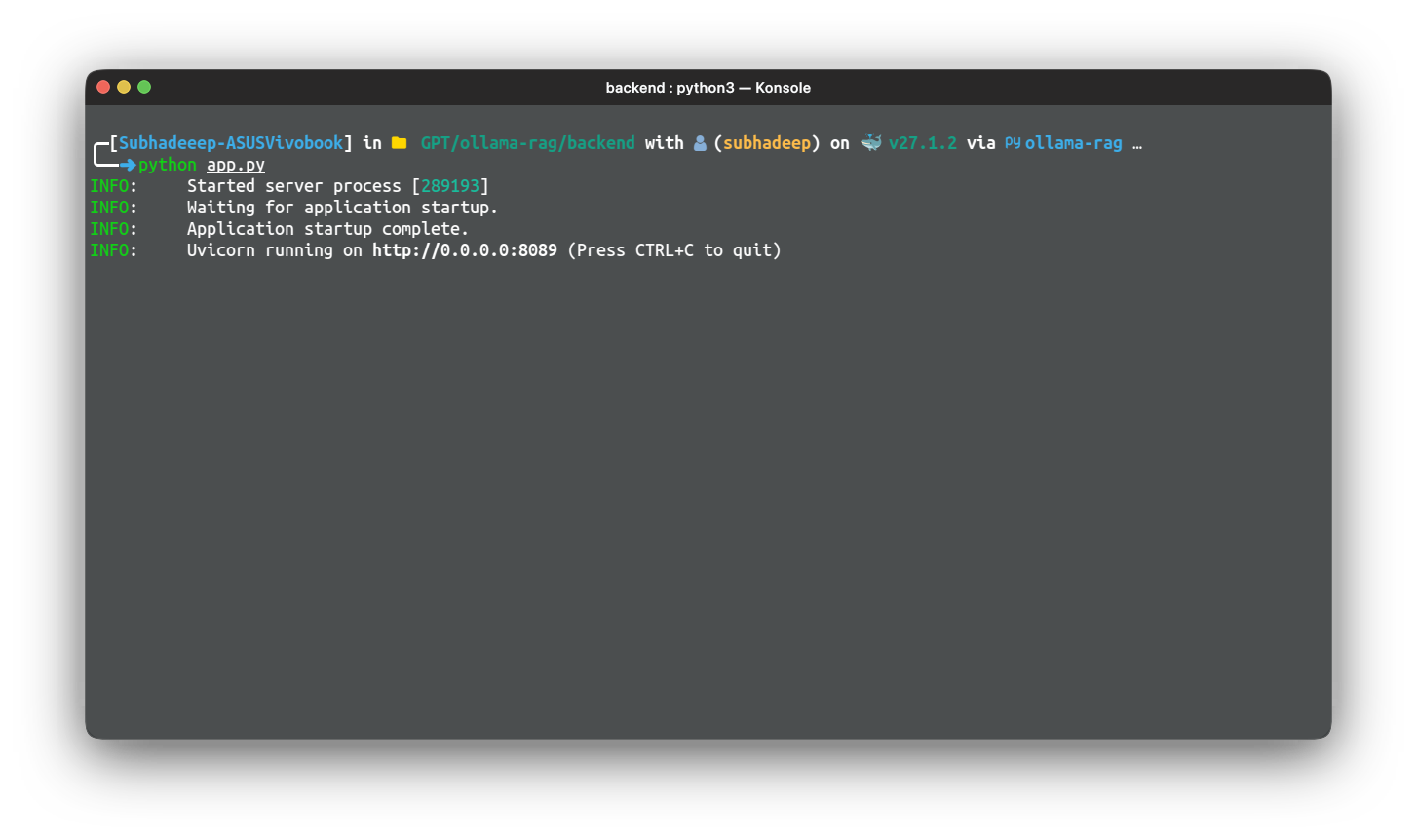
از یک IDE تست API مانند Postman، Insomnia یا Bruno برای آزمایش برنامه استفاده کنید. همچنین می توانید از افزونه Thunder Client برای انجام همین کار استفاده کنید.
آزمایش نقطه پایان پذیرش:
تست نقطه پایانی درخواست:
طراحی قسمت جلویی با Reflex
ما با موفقیت یک برنامه FastAPI برای باطن برنامه RAG خود ایجاد کردیم. وقت آن است که قسمت جلویی خود را بسازیم. شما میتوانید هر کتابخانه فرانتاندی را برای این کار انتخاب کنید، اما برای این مقاله خاص، قسمت جلویی را با استفاده از Reflex میسازیم. Reflex یک کتابخانه front-end فقط پایتون است که برای ساخت برنامه های وب به طور کامل با استفاده از Python ساخته شده است. با الگوهایی برای برنامه های معمولی مانند ماشین حساب، تولید تصویر و چت بات به ما ثابت می کند. ما از الگوی برنامه چت بات به عنوان نقطه شروع برای رابط کاربری خود استفاده خواهیم کرد. برنامه نهایی ما ساختار زیر را خواهد داشت، بنابراین بیایید آن را برای مرجع در اینجا داشته باشیم.
دایرکتوری Frontend
ما یک دایرکتوری جلویی برای این کار خواهیم داشت:
frontend
├── assets
│ └── favicon.ico
├── docs
│ └── demo.gif
├── chat
│ ├── components
│ │ ├── chat.py
│ │ ├── file_upload.py
│ │ ├── __init__.py
│ │ ├── loading_icon.py
│ │ ├── modal.py
│ │ └── navbar.py
│ ├── __init__.py
│ ├── chat.py
│ └── state.py
├── requirements.txt
├── rxconfig.py
└── uploaded_filesمراحل درخواست نهایی
مراحل را دنبال کنید تا زمینه برای برنامه نهایی آماده شود.
مرحله 1: مخزن قالب چت را در فهرست رابط کلون کنید
git clone https://github.com/reflex-dev/reflex-chat.git .مرحله 2: دستور زیر را برای مقداردهی اولیه دایرکتوری به عنوان یک برنامه رفلکس اجرا کنید
reflex init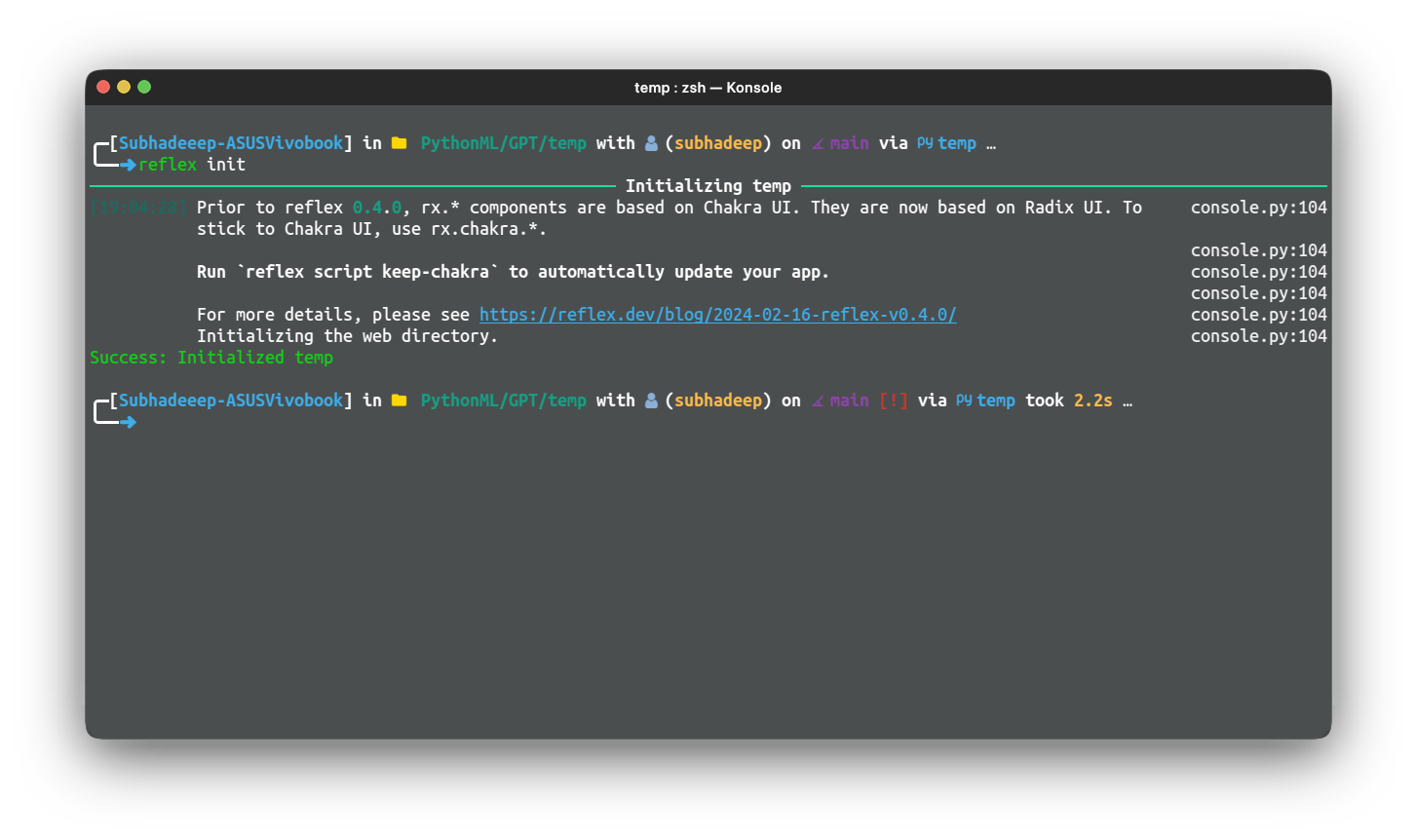
این برنامه Reflex را راه اندازی می کند و آماده اجرا و توسعه خواهد بود.
مرحله 3: برنامه را آزمایش کنید، از دستور زیر از دایرکتوری داخلی رابط استفاده کنید
reflex run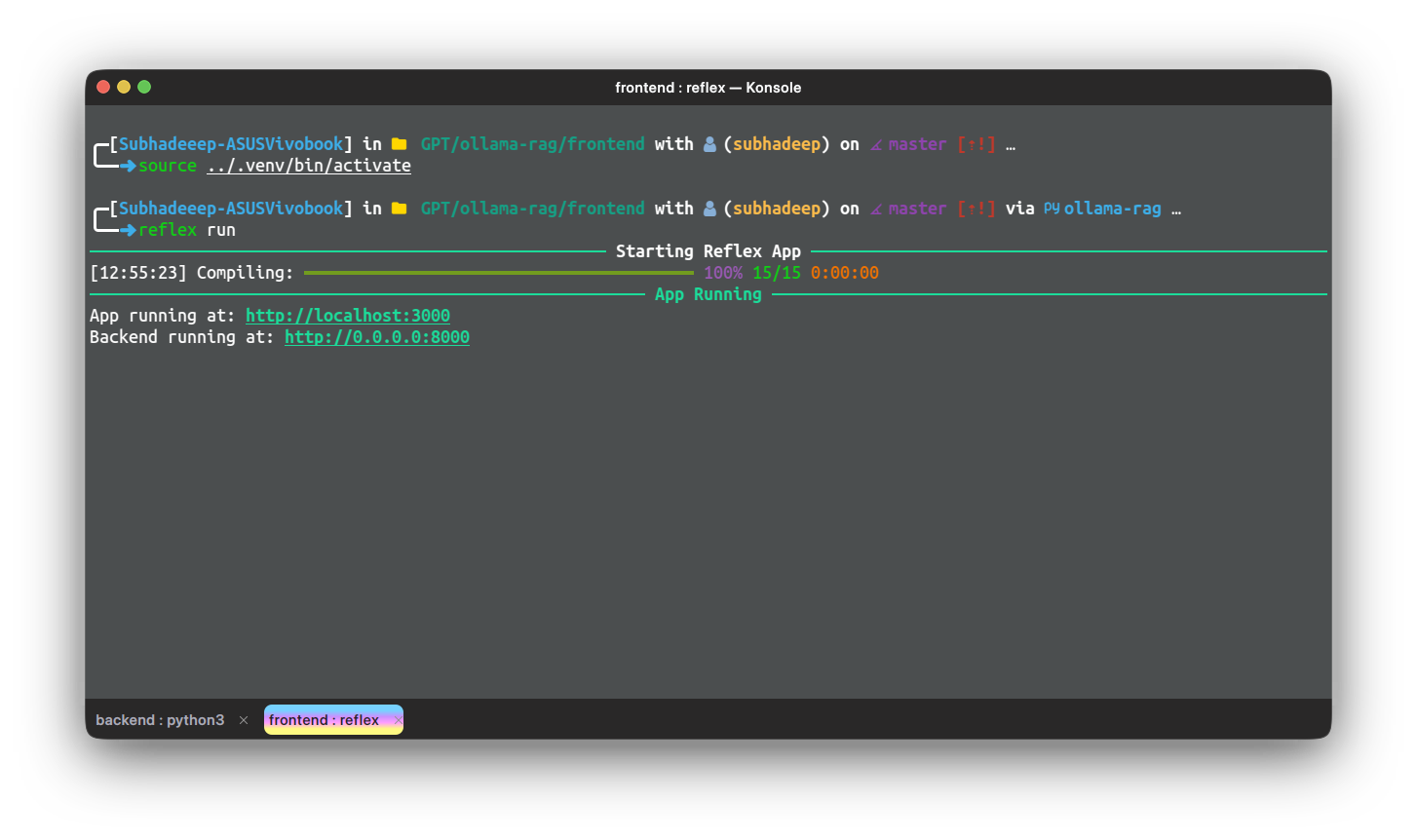
بیایید اصلاح اجزا را شروع کنیم. ابتدا اجازه دهید فایل chat.py را اصلاح کنیم.
در زیر کد مربوط به همین مورد است:
import reflex as rx
from reflex_demo.components import loading_icon
from reflex_demo.state import QA, State
message_style = dict(
display="inline-block",
padding="0 10px",
border_radius="8px",
max_width=["30em", "30em", "50em", "50em", "50em", "50em"],
)
def message(qa: QA) -> rx.Component:
"""A single question/answer message.
Args:
qa: The question/answer pair.
Returns:
A component displaying the question/answer pair.
"""
return rx.box(
rx.box(
rx.markdown(
qa.question,
background_color=rx.color("mauve", 4),
color=rx.color("mauve", 12),
**message_style,
),
text_align="right",
margin_top="1em",
),
rx.box(
rx.markdown(
qa.answer,
background_color=rx.color("accent", 4),
color=rx.color("accent", 12),
**message_style,
),
text_align="left",
padding_top="1em",
),
width="100%",
)
def chat() -> rx.Component:
"""List all the messages in a single conversation."""
return rx.vstack(
rx.box(rx.foreach(State.chats[State.current_chat], message), width="100%"),
py="8",
flex="1",
width="100%",
max_width="50em",
padding_x="4px",
align_self="center",
overflow="hidden",
padding_bottom="5em",
)
def action_bar() -> rx.Component:
"""The action bar to send a new message."""
return rx.center(
rx.vstack(
rx.chakra.form(
rx.chakra.form_control(
rx.hstack(
rx.input(
rx.input.slot(
rx.tooltip(
rx.icon("info", size=18),
content="Enter a question to get a response.",
)
),
placeholder="Type something...",
id="question",
width=["15em", "20em", "45em", "50em", "50em", "50em"],
),
rx.button(
rx.cond(
State.processing,
loading_icon(height="1em"),
rx.text("Send", font_family="Ubuntu"),
),
type="submit",
),
align_items="center",
),
is_disabled=State.processing,
),
on_submit=State.process_question,
reset_on_submit=True,
),
rx.text(
"ReflexGPT may return factually incorrect or misleading responses. Use discretion.",
text_align="center",
font_size=".75em",
color=rx.color("mauve", 10),
font_family="Ubuntu",
),
rx.logo(margin_top="-1em", margin_bottom="-1em"),
align_items="center",
),
position="sticky",
bottom="0",
left="0",
padding_y="16px",
backdrop_filter="auto",
backdrop_blur="lg",
border_top=f"1px solid {rx.color('mauve', 3)}",
background_color=rx.color("mauve", 2),
align_items="stretch",
width="100%",
)تغییرات نسبت به تغییرات اولیه در قالب بسیار کم است.
در مرحله بعد، ما برنامه chat.py را ویرایش می کنیم. این جزء اصلی چت است.
کد برای جزء اصلی چت
در زیر کد آن آمده است:
import reflex as rx
from reflex_demo.components import chat, navbar, upload_form
from reflex_demo.state import State
@rx.page(route="/chat", title="RAG Chatbot")
def chat_interface() -> rx.Component:
return rx.chakra.vstack(
navbar(),
chat.chat(),
chat.action_bar(),
background_color=rx.color("mauve", 1),
color=rx.color("mauve", 12),
min_height="100vh",
align_items="stretch",
spacing="0",
)
@rx.page(route="https://www.analyticsvidhya.com/", title="RAG Chatbot")
def index() -> rx.Component:
return rx.chakra.vstack(
navbar(),
upload_form(),
background_color=rx.color("mauve", 1),
color=rx.color("mauve", 12),
min_height="100vh",
align_items="stretch",
spacing="0",
)
# Add state and page to the app.
app = rx.App(
theme=rx.theme(
appearance="dark",
accent_color="jade",
),
stylesheets=["https://fonts.googleapis.com/css2?family=Ubuntu&display=swap"],
style={
"font_family": "Ubuntu",
},
)
app.add_page(index)
app.add_page(chat_interface)این کد رابط چت است. ما فقط خانواده فونت را به پیکربندی برنامه اضافه کردیم، بقیه کدها به همین صورت است.
بعد، اجازه دهید فایل state.py را ویرایش کنیم. این جایی است که رابط با نقاط پایانی API پاسخ تماس می گیرد.
فایل state.py را ویرایش کنید
import requests
import reflex as rx
class QA(rx.Base):
question: str
answer: str
DEFAULT_CHATS = {
"Intros": [],
}
class State(rx.State):
chats: dict[str, list[QA]] = DEFAULT_CHATS
current_chat = "Intros"
url: str = "http://localhost:8089/query"
question: str
processing: bool = False
new_chat_name: str = ""
def create_chat(self):
"""Create a new chat."""
# Add the new chat to the list of chats.
self.current_chat = self.new_chat_name
self.chats[self.new_chat_name] = []
def delete_chat(self):
"""Delete the current chat."""
del self.chats[self.current_chat]
if len(self.chats) == 0:
self.chats = DEFAULT_CHATS
self.current_chat = list(self.chats.keys())[0]
def set_chat(self, chat_name: str):
"""Set the name of the current chat.
Args:
chat_name: The name of the chat.
"""
self.current_chat = chat_name
@rx.var
def chat_titles(self) -> list[str]:
"""Get the list of chat titles.
Returns:
The list of chat names.
"""
return list(self.chats.keys())
async def process_question(self, form_data: dict[str, str]):
# Get the question from the form
question = form_data["question"]
# Check if the question is empty
if question == "":
return
model = self.openai_process_question
async for value in model(question):
yield value
async def openai_process_question(self, question: str):
"""Get the response from the API.
Args:
form_data: A dict with the current question.
"""
# Add the question to the list of questions.
qa = QA(question=question, answer="")
self.chats[self.current_chat].append(qa)
payload = {"question": question}
# Clear the input and start the processing.
self.processing = True
yield
response = requests.post(self.url, json=payload, stream=True)
# Stream the results, yielding after every word.
for answer_text in response.iter_content(chunk_size=512):
# Ensure answer_text is not None before concatenation
answer_text = answer_text.decode()
if answer_text is not None:
self.chats[self.current_chat][-1].answer += answer_text
else:
answer_text = ""
self.chats[self.current_chat][-1].answer += answer_text
self.chats = self.chats
yield
# Toggle the processing flag.
self.processing = Falseدر این فایل ما URL را برای نقطه پایانی درخواست تعریف کرده ایم. ما همچنین روش openai_process_question را برای ارسال یک درخواست POST به نقطه پایانی درخواست و دریافت جریان تغییر دادیم.
پاسخی که در رابط چت نمایش داده می شود.
ذخیره محتویات فایل file_upload.py
در نهایت اجازه دهید محتویات فایل file_upload.py را بنویسیم. این مؤلفه در ابتدا نمایش داده می شود و به ما امکان می دهد فایل پذیرش را بارگذاری کنیم.
import reflex as rx
import os
import time
import requests
class UploadExample(rx.State):
uploading: bool = False
ingesting: bool = False
progress: int = 0
total_bytes: int = 0
ingestion_url = "http://127.0.0.1:8089/ingest"
async def handle_upload(self, files: list[rx.UploadFile]):
self.ingesting = True
yield
for file in files:
file_bytes = await file.read()
file_name = file.filename
files = {
"file": (os.path.basename(file_name), file_bytes, "multipart/form-data")
}
response = requests.post(self.ingestion_url, files=files)
self.ingesting = False
yield
if response.status_code == 200:
# yield rx.redirect("/chat")
self.show_redirect_popup()
def handle_upload_progress(self, progress: dict):
self.uploading = True
self.progress = round(progress["progress"] * 100)
if self.progress >= 100:
self.uploading = False
def cancel_upload(self):
self.uploading = False
return rx.cancel_upload("upload3")
def upload_form():
return rx.vstack(
rx.upload(
rx.flex(
rx.text(
"Drag and drop file here or click to select file",
font_family="Ubuntu",
),
rx.icon("upload", size=30),
direction="column",
align="center",
),
id="upload3",
border="1px solid rgb(233, 233,233, 0.4)",
margin="5em 0 10px 0",
background_color="rgb(107,99,246)",
border_radius="8px",
padding="1em",
),
rx.vstack(rx.foreach(rx.selected_files("upload3"), rx.text)),
rx.cond(
~UploadExample.ingesting,
rx.button(
"Upload",
on_click=UploadExample.handle_upload(
rx.upload_files(
upload_id="upload3",
on_upload_progress=UploadExample.handle_upload_progress,
),
),
),
rx.flex(
rx.spinner(size="3", loading=UploadExample.ingesting),
rx.button(
"Cancel",
on_click=UploadExample.cancel_upload,
),
align="center",
spacing="3",
),
),
rx.alert_dialog.root(
rx.alert_dialog.trigger(
rx.button("Continue to Chat", color_scheme="green"),
),
rx.alert_dialog.content(
rx.alert_dialog.title("Redirect to Chat Interface?"),
rx.alert_dialog.description(
"You will be redirected to the Chat Interface.",
size="2",
),
rx.flex(
rx.alert_dialog.cancel(
rx.button(
"Cancel",
variant="soft",
color_scheme="gray",
),
),
rx.alert_dialog.action(
rx.button(
"Continue",
color_scheme="green",
variant="solid",
on_click=rx.redirect("/chat"),
),
),
spacing="3",
margin_top="16px",
justify="end",
),
style={"max_width": 450},
),
),
align="center",
)این کامپوننت به ما امکان می دهد یک فایل را آپلود کرده و آن را در مخزن برداری وارد کنیم. از نقطه پایانی پذیرش برنامه FastAPI ما برای آپلود و پذیرش فایل استفاده می کند. پس از مصرف، کاربر به سادگی می تواند حرکت کند
به رابط چت برای پرسیدن سوال.
این کار ساخت قسمت جلویی برنامه ما را تکمیل می کند. اکنون باید برنامه را با استفاده از یک سند آزمایش کنیم.
تست و استقرار
حالا بیایید برنامه را روی برخی از راهنماها یا اسناد آزمایش کنیم. برای استفاده از اپلیکیشن، باید هم اپلیکیشن back-end و هم اپلیکیشن reflex را جداگانه اجرا کنیم. برنامه Backend را با استفاده از دایرکتوری خود اجرا کنید
دستور زیر:
python app.pyمنتظر بمانید تا FastAPI شروع به کار کند. سپس، در یک نمونه ترمینال دیگر، برنامه را از قسمت جلو با استفاده از دستور زیر اجرا کنید:
reflex runپس از راهاندازی برنامهها، برای دسترسی به برنامه رفلکس به آدرس زیر رسیدم. ما ابتدا در صفحه آپلود فایل خواهیم بود. یک فایل را آپلود کنید و دکمه آپلود را فشار دهید.
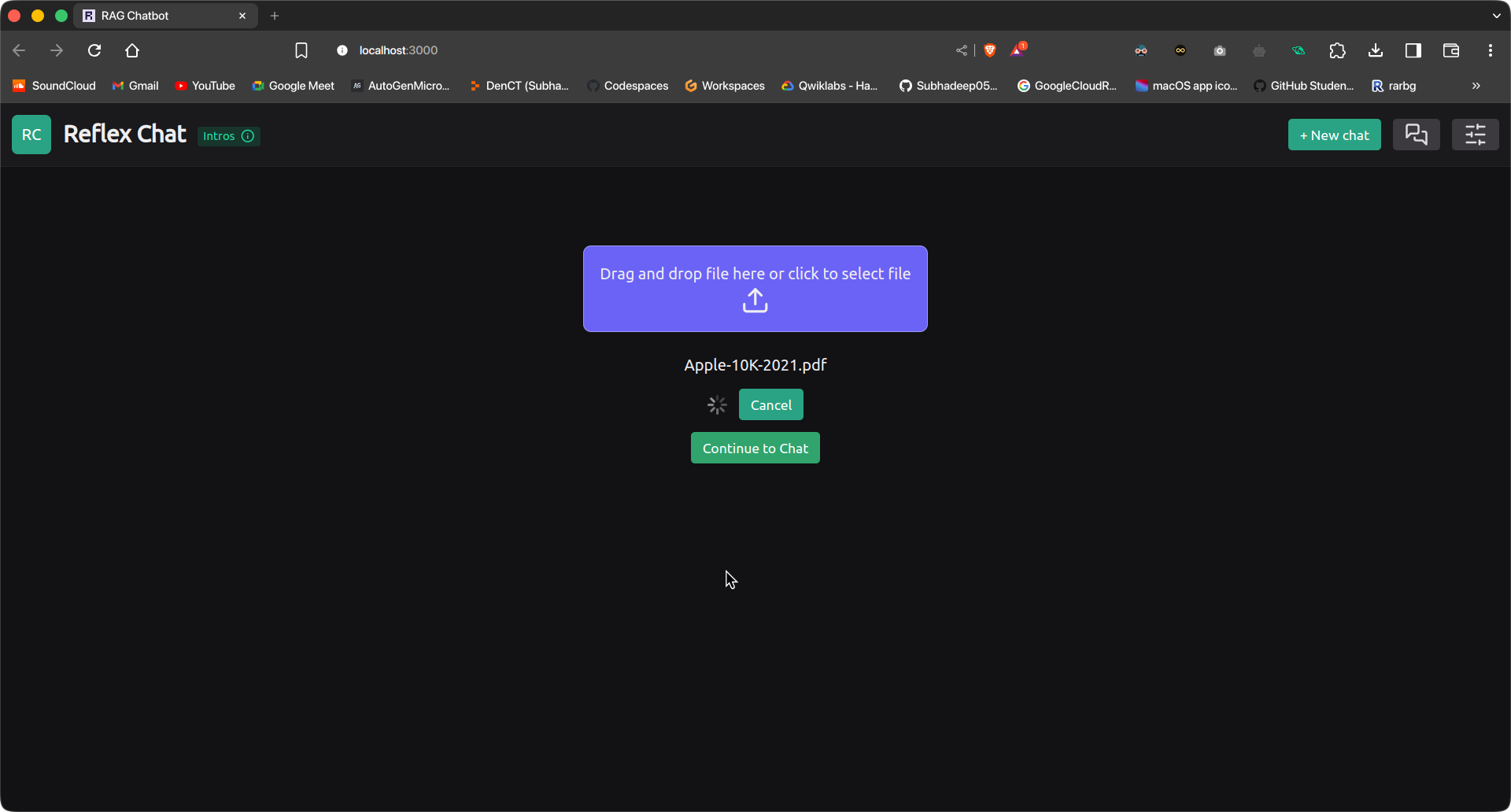
فایل آپلود و دانلود خواهد شد. این کار بسته به اندازه سند و
مشخصات دستگاه پس از انجام این کار، روی دکمه “Proceed to Chat” کلیک کنید تا وارد رابط چت شوید. درخواست خود را بنویسید و ارسال را فشار دهید.
نتیجه گیری
در این مجموعه دو قسمتی، شما قبلاً یک برنامه RAG کامل و کاربردی را روی Raspberry Pi ساختهاید، از ایجاد خط لوله اصلی تا بستهبندی آن با یک بکاند FastAPI و توسعه یک صفحه جلویی مبتنی بر Reflex. با این ابزارها، خط لوله RAG شما قابل دسترسی و تعاملی است و پردازش درخواست را در زمان واقعی از طریق یک رابط وب کاربر پسند ارائه می دهد. با تسلط بر این مراحل، تجربه ارزشمندی در ساخت و استقرار برنامههای کاربردی سرتاسر بر روی یک پلتفرم فشرده و کارآمد به دست آوردهاید. این راهاندازی در را به روی امکانات بیشماری برای پیادهسازی برنامههای مبتنی بر هوش مصنوعی بر روی دستگاههای دارای محدودیت منابع مانند Raspberry Pi باز میکند و فناوری پیشرفتهتر را برای استفاده روزمره در دسترستر و کاربردیتر میکند.
یافته های کلیدی
- راهنمای دقیقی برای راه اندازی محیط توسعه ارائه شده است، از جمله نصب وابستگی ها و مدل های لازم با استفاده از Ollama، اطمینان از آماده بودن برنامه برای ساخت نهایی.
- این مقاله نحوه قرار دادن خط لوله RAG را در یک برنامه FastAPI، از جمله راهاندازی نقاط پایانی پرس و جو برای مدل و دریافت اسناد، و قابل دسترس کردن خط لوله از طریق یک API وب توضیح میدهد.
- قسمت جلویی برنامه RAG با استفاده از Reflex ساخته شده است، یک کتابخانه جلویی فقط پایتون. این مقاله نشان می دهد که چگونه می توان قالب برنامه چت را برای ایجاد یک رابط کاربر پسند برای تعامل با خط لوله RAG تغییر داد.
- این مقاله راهنمای ادغام باطن FastAPI با پیشفرض Reflex و استقرار برنامه کامل بر روی Raspberry Pi است که عملکرد یکپارچه و دسترسی را برای کاربران تضمین میکند.
- مراحل عملی برای آزمایش هر دو نقطه انتهایی دریافت و درخواست با استفاده از ابزارهایی مانند Postman یا Thunder Client، همراه با اجرای و آزمایش قسمت جلویی Reflex برای اطمینان از عملکرد کل برنامه همانطور که انتظار می رود، ارائه شده است.
سوال متداول
الف. پلتفرمی به نام Tailscale وجود دارد که به دستگاه های شما اجازه می دهد به یک شبکه امن خصوصی وصل شوند که فقط برای شما قابل دسترسی است. میتوانید Raspberry Pi و سایر دستگاههای خود را به دستگاههای Tailscale اضافه کنید و برای دسترسی به برنامههای خود از هر کجای دنیا به VPN متصل شوید.
A. این محدودیت به دلیل مشخصات سخت افزاری پایین Raspberry Pi است. این مقاله فقط یک آموزش شروع کننده در مورد نحوه شروع ساخت یک برنامه RAG با استفاده از Raspberry Pi و Olama است.
رسانه نمایش داده شده در این مقاله متعلق به Analytics Vidhya نیست و بنا به صلاحدید نویسنده استفاده می شود.